There are many debates about which type of database is better. I will focus on how to use them for a specific case and how to evolve the design as needed.
SQL vs NoSQL
There are many types of databases and each of them fits better for a different scenario. For example MySQL works well for the normal usage of a website as it is quite balanced, Redshift works great as a data warehouse for reporting as it offers very fast read access and a structured data format, and MongoDB can support an application that handles thousands of orders per second as it quite fast and scales via sharding.
Organisations used to choose only one type but the appearance of microservices has allowed to use a combination of them, and in some cases more than one for the same data as happens with CQRS. The only limitations are now the learning curve and the people needed to maintain them. The maintenance effort can be nearly zero with databases as a service like DynamoDB but can be quite high with others like Cassandra, so it is an important factor to consider.
The case to consider
I am going to focus on a very specific case that is how to model the data of a user registration form. I will start by a basic scenario that fits well in a structured table and will progress until the point where it is better to migrate it to a more flexible format.
I will mention basic types like string but all the fields should be stored encrypted. They contain personal information that would be leaked if a hacker got access to the database and the data was in plain text.
1) The basic scenario
Let’s assume that we have a basic screen with a fixed set of fields that are the same for each user. For example Name, Age and Country.
It is obvious that Name would be a string and Age would be a number. Country could be modelled as a string, but it would be problematic because each person may write it in a different way (“Spain”, “spain”, “España”, …) and we would have multiple occurrences of the same. It would also be difficult to filter by it in a user listing. Due to this it would be better to have a separate table with a list of countries and an identifier pointing to it. This would also allow to have a dropdown field in the form to select the country from a list instead of having to type its name.
The structure would be something like this:
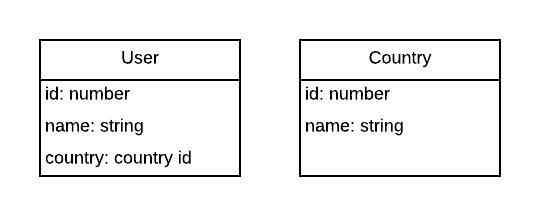
This could be stored perfectly fine in MySQL and it would be very easy to run reporting queries on it. It would also be quite easy to detect if the country id doesn’t exist using a foreign key. We could also add some restrictions on the database level like the maximum name length of the name or making the age optional or mandatory, although that should be also validated in the back end code before doing the queries.
2) Adding some flexibility per customer
Let’s say that we have a SaaS application and we onboard a couple of customers that have slightly different needs for storing the data of their employees. For example customer A
may need to store in which office will the employee work and customer B may want to store the employee’s manager.
There are just a couple of fields what doesn’t require big changes and other customers may also want to use them in the future. We could just add a couple of optional columns to the table. In case that the columns are mandatory per customer we could add a validation in the application code. We could also add a constraint in the schema based on the customer but that would affect slightly the performance for all the customers.
The user table could be something like this now:

3) Adding total flexibility using a SQL database
Let’s suppose that our SaaS application is quite successful and we get more big customers. One of them may want to store “Phone number”, “Email address”, “Family size”, “Requires visa” … while other may need “Cost centre”, “Payroll code”, …
The structured schema that we had before wouldn’t work anymore as we would reach very quickly the maximum number of columns per table that the database supports. The table would be also unnecessary big and most of the cells would be empty. We could choose a couple of approaches assuming that we want to keep using the same database.
3.1) Have a different table per customer:
If only two big customers have these requirements and the others are happy to use the standard columns, we could have the common ones in one table and the different ones in separate ones. For example:

The problem with this is that it doesn’t scale. It would make quite complicate the back end logic as we would need different queries per customer. Imagine with hundreds of customers…
3.2) Have a flexible structure using key/value pairs:
If each customer needs a completely different set of columns we could have the common fields in a separate table and then use a shared one. The specific ones could be in a key value pair in which each row would represent a field of each user. Each row may store a string, a number, a boolean value, … so we have to consider it.
The structure would be:
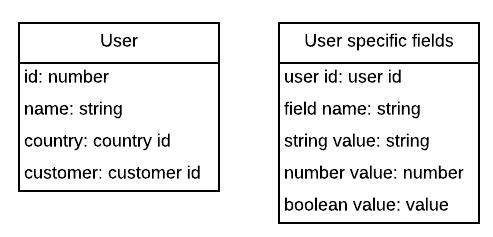
And the data would look like this:
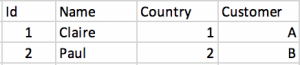

This would give us the flexibility needed and would scale and support any number of customers. It would also allow to keep using the same database what is perfect if we are using a monolith or there are some related tables that are used by the same service and cannot be modified.
However it is not a very desirable solution as we would need dozens of rows per employee. It would also complicate the application code as we would have to retrieve all of them and combine the data in the back end.
4) Using instead a NoSQL database
This databases offer the flexibility needed as they don’t have a rigid schema. We could have a different structure per customer what would be like this:
User example for customer A:
{
id: 1,
name: Claire,
country: 1,
customer: A,
phone number: “077070707”,
email address: “claire@email.com”,
family size: 3,
requires visa: yes,
…
}
User example for customer B:
{
id: 2,
name: Paul,
country: 2,
customer: B,
cost centre: “London Office”,
payroll code: “PAY-123″,
…
}
This solution would be quite simple to implement in the backend as the queries would just store and retrieve users without caring too much about the data structure.
The challenge of this approach is to do reporting or data analysis queries. A way of doing it would be copying the data to a more structured format for example in the ETL layer.
Conclusion
We have seen different ways of structuring the data depending on the evolving needs of the application. There isn’t a solution that fits perfectly for the most complex case so it is up to the team to discuss the trade offs and choose it based on the architecture and the flexibility and cost of combining different technologies
Consultant and security champion specialised in Java, with experience in architecture and team management in both startups and big corporations.
Disclaimer: the posts are based on my own experience and may not reflect the views of my current or any previous employer


